数据模型架构规范是大数据项目开发的重要基础 📊,为后续开发工作提供规范及指导建议。本文基于阿里云云原生大数据计算平台的最佳实践,介绍完整的数据模型架构规范。
🏗️ 数据层次划分
ODS层 - 操作数据层
Operational Data Store
- 📥 功能定位:数据准备区,基础数据记录和历史变化追踪
- 🔄 数据特点:与源系统增量或全量数据结构基本一致
- 🎯 主要作用:将基础数据引入到MaxCompute等大数据平台
CDM层 - 公共维度模型层
Common Data Model
- 🎯 核心功能:数据加工整合、建立一致性维度、构建可复用的分析统计表
- 📋 细分层次:
- DWD(Data Warehouse Detail):明细数据层
- DWS(Data Warehouse Summary):汇总数据层
ADS层 - 应用数据层
Application Data Service
- 🚀 服务对象:直接面向业务应用和数据产品
- 📊 数据特点:高度聚合的主题数据
💡 注意:具体的仓库分层需要结合业务场景、数据场景、系统场景进行综合考虑。
📊 数据分类架构
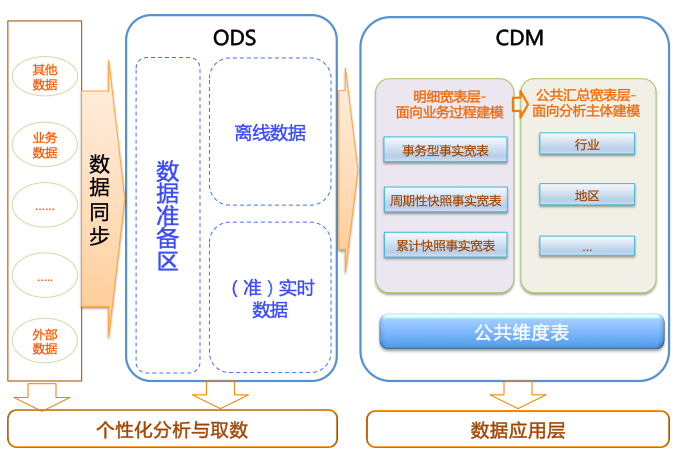
ODS层架构组成
数据分类架构在ODS层分为三个核心部分:
- 🔧 数据准备区:原始数据接入和预处理
- 💾 离线数据区:批量数据存储和处理
- ⚡ 准实时数据区:流式数据处理
CDM层架构组成
🏛️ 公共维度层
- 基于维度建模理念,建立企业级一致性维度
- 确保维度数据的标准化和复用性
📋 明细粒度事实层
- 以业务过程为建模驱动
- 构建最细粒度的明细层事实表
- 支持宽表化处理,冗余重要维度属性
📈 公共汇总粒度事实层
- 以分析主题对象为建模驱动
- 基于上层应用和产品指标需求
- 构建公共粒度的汇总指标事实表
数据处理流程架构
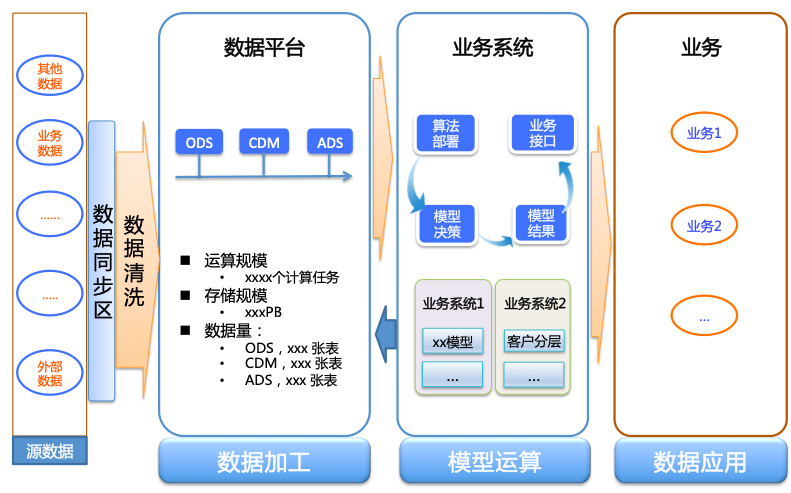
数据划分及命名空间约定
请根据业务划分数据并约定命名,建议针对业务名称结合数据层次约定相关命名的英文缩写,这样可以给后续数据开发过程中,对项目空间、表、字段等命名做为重要参照。
- 按业务划分:命名时按主要的业务划分,以指导物理模型的划分原则、命名原则及使用的ODS project。例如,按业务定义英文缩写,阿里的“淘宝”英文缩写可以定义为“tb”。
- 按数据域划分:命名时按照CDM层的数据进行数据域划分,以便有效地对数据进行管理,以及指导数据表的命名。例如,“交易”数据的英文缩写可定义为“trd”。
- 按业务过程划分:当一个数据域由多个业务过程组成时,命名时可以按业务流程划分。业务过程是从数据分析角度看客观存在的或者抽象的业务行为动作。例如,交易数据域中的“退款”这个业务过程的英文缩写可约定命名为“rfd_ent”。
数据模型
模型是对现实事物的反映和抽象,能帮助我们更好地了解客观世界。数据模型定义了数据之间关系和结构,使得我们可以有规律地获取想要的数据。例如,在一个超市里,商品的布局都有特定的规范,商品摆放的位置是按照消费者的购买习惯以及人流走向进行摆放的。
-
数据模型的作用
数据模型是在业务需求分析之后,数据仓库工作开始时的第一步。良好的数据模型可以帮助我们更好地存储数据,更有效率地获取数据,保证数据间的一致性。
-
模型设计的基本原则
-
高内聚和低耦合
一个逻辑和物理模型由哪些记录和字段组成,应该遵循最基本的软件设计方法论中的高内聚和低耦合原则。主要从数据业务特性和访问特性两个角度来考虑:将业务相近或者相关的数据、粒度相同数据设计为一个逻辑或者物理模型;将高概率同时访问的数据放一起,将低概率同时访问的数据分开存储。
-
核心模型与扩展模型分离
建立核心模型与扩展模型体系,核心模型包括的字段支持常用核心的业务,扩展模型包括的字段支持个性化或是少量应用的需要。在必须让核心模型与扩展模型做关联时,不能让扩展字段过度侵入核心模型,以免破坏了核心模型的架构简洁性与可维护性。
-
公共处理逻辑下沉及单一
底层公用的处理逻辑应该在数据调度依赖的底层进行封装与实现,不要让公用的处理逻辑暴露给应用层实现,不要让公共逻辑在多处同时存在。
-
成本与性能平衡
适当的数据冗余可换取查询和刷新性能,不宜过度冗余与数据复制。
-
数据可回滚
处理逻辑不变,在不同时间多次运行数据的结果需确定不变。
-
一致性
相同的字段在不同表中的字段名必须相同。
-
命名清晰可理解
表命名规范需清晰、一致,表命名需易于下游的理解和使用。
-
说明
- 一个模型无法满足所有的需求。
- 需合理选择数据模型的建模方式。
- 通常,设计顺序依次为:概念模型->逻辑模型->物理模型。
参考:https://help.aliyun.com/zh/maxcompute/use-cases/data-model-architecture-specifications